Lecture 18 Multi-Version Concurrency Control
MVCC Overview
Multi - Version Concurrency Control 多版本并发控制
最好的理解方式是,它是一个在高层次上有两个组件的协议: 当我改变事物时,我如何管理这些变化?
截止到目前,我们所阐释的是有两种方法可以实现: 一是我将直接在两阶段锁定机制中进行原地更新,该机制之前是隐式的,现在我将获取一个写锁,确保在我进行修改,其他人无法修改。二是在OCC中,操作类似于制作副本,在副本中修改,最终在写入阶段时写入。
现在开始运用这些理念,进而探讨如何将他们融会贯通,并探究在全球数据库中如何实现这一过程。
所有这些工作区检查,核对等操作过于繁琐,我们将使用时间戳等工具,并保留版本链,以便能够来回切换
可以分为两个部分,一方面是我们如何管理版本,即MV部分; 另一方面,CC部分涉及到我们仍然需要类似2PL, OCC等机制以确保两个写者之间不会相互干扰对方的操作
今天我们所探讨的内容,源自于1978年麻省理工的一篇论文,以及背后的庞大历史
MVCC背后的主要思想是什么呢?我们将构建系统,使得写入这不会有效阻塞读者,我们会创建新的版本,因此读者也不会阻塞写者。
将会运用一种snapshot(快照)的概念,快照类似于OCC协议中的检入检出操作时获取的状态。这就像是说,设想我能在每次事物开始时都逻辑上复制一个数据库,注意是逻辑上的,实际上,我得到了一个快照,并可以再次基础上进行操作,所以说别人操作的时候将不会影响最初的内容,仿佛在数据库所做的一切都处于起始阶段,当进行写操作的时候,必须遵循所有这些验证风格的协议,以确定下一个快照需要呈现的样子 这种现象有一个专门的名词叫 snapshot isolation(快照隔离)
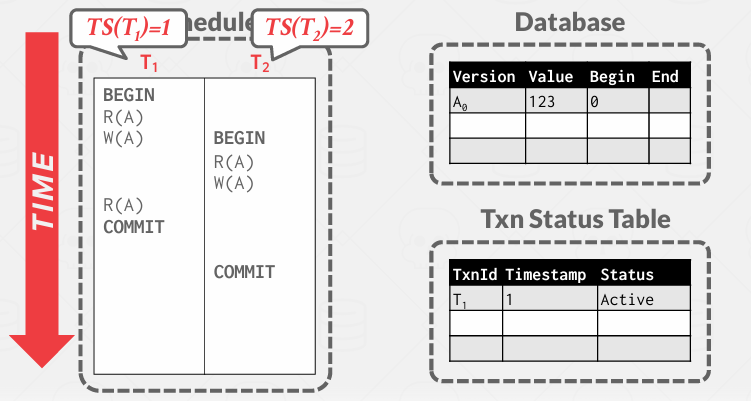
Example 1
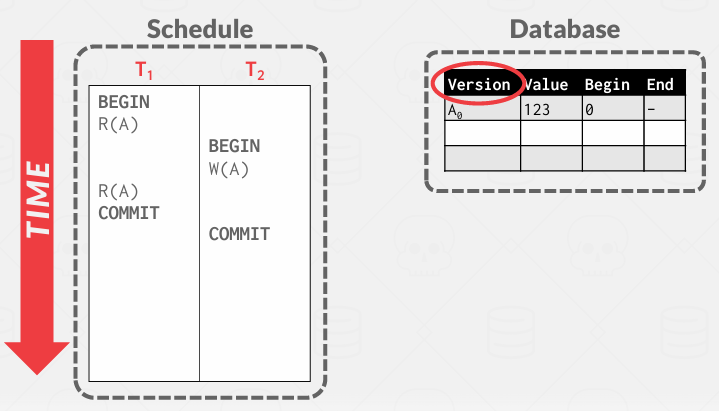
这是一个MVCC的例子,有两个事务, 暂时将Database中的值视为一条记录,这个记录的值不会随着事务的执行而改变,而是关联一个时间戳.
这里事务分配的是1和2
图中的Version只是为了让ppt更好理解,本质上是在说"我是记录A,然后是其第0版"
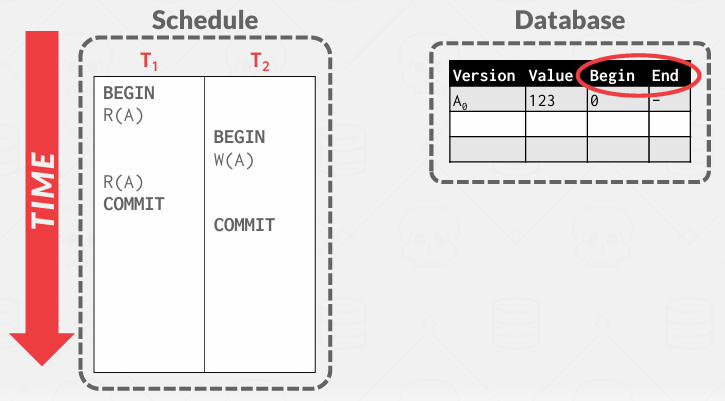
Begin, End是起始和结束的时间戳
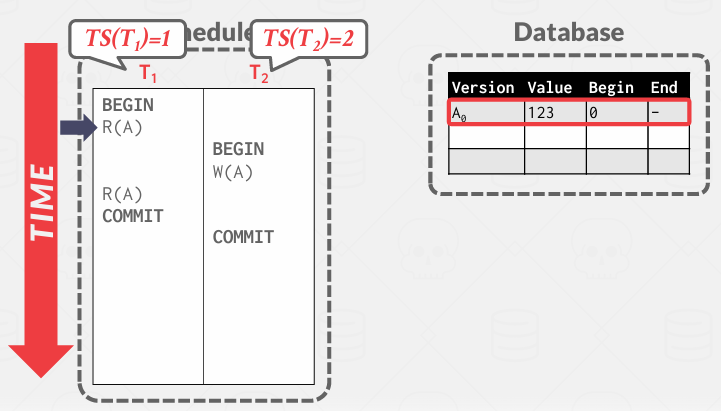
ReadA 操作,这里只有一个Version, 所以他会去查看这个Version并表示将检查开始时间戳,并声明自己是1 我可以阅读这个嘛?, 结束时间戳是无穷大, 本质上, 这意味着当前数据库的状态, 即我们所见的快照, 是从过去的某个时刻开始,其值设定为时间零点, 而且就目前而言,它将在未来持续运行……
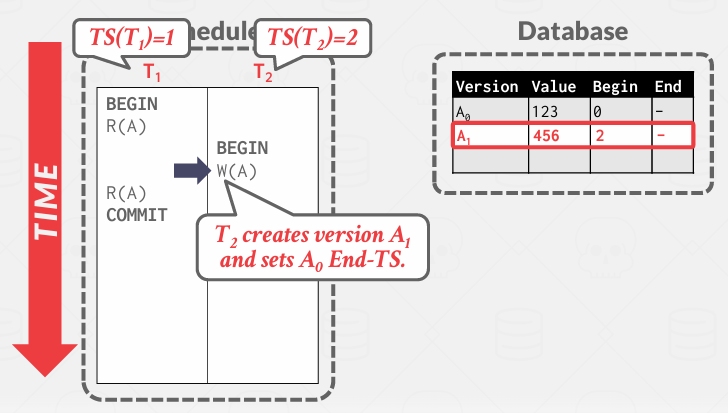
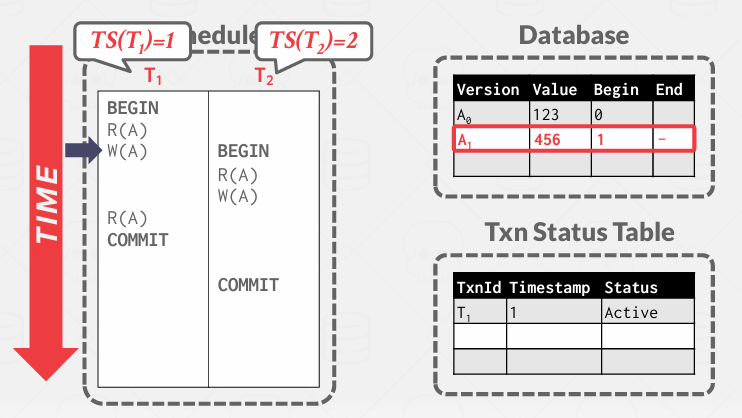
Write A, 实际上它将在同一表中创建该记录的副本, 没有覆盖旧的内容。
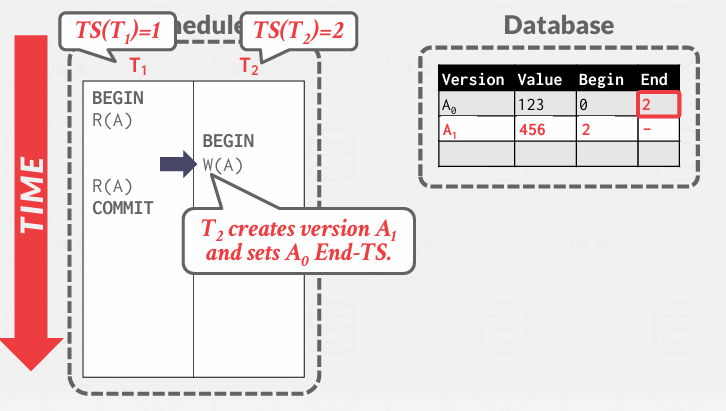
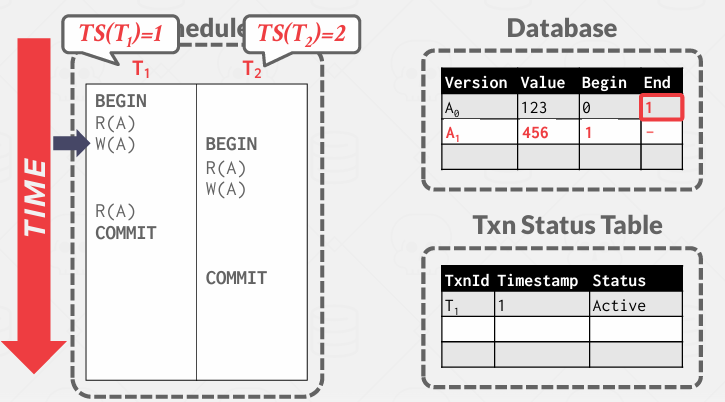
然后对旧的内容修正,证明它最终停在了2
任何时间戳小于2的事务将读取第一个版本, 所有第时间戳大于2的事务都将访问第二个版本,但是第二个版本还没有完成,当完成的时候,会在其中添加一个结束时间戳
这个就像GitHub上特定文件的历史记录一样,精确指明了什么时间在哪些内容是有效的
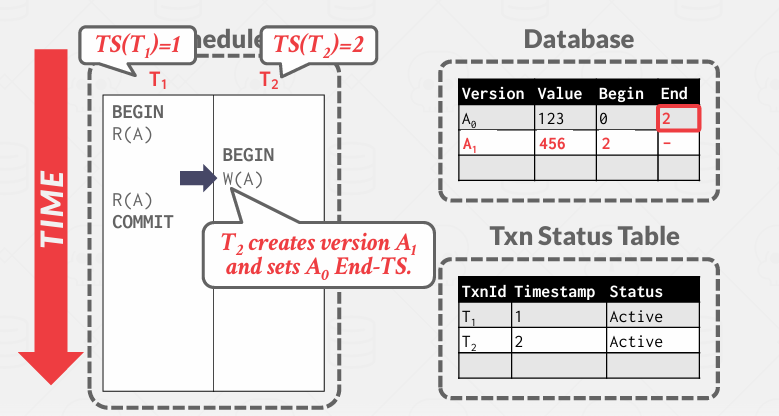
除此之外, 还需要一些额外的机制,即一个事务表,用于记录该事物的进展情况
假如我要开始读取A1的版本的a的值,我需要知道它是否有效或者已经被提交, 如果commit了 则可以去引用他. 当然随着进展还可能进入终止阶段abort.
当一个新的事务试图访问这些版本链, 会看到这些范围的开始和结束,这件告诉事务是否允许看到它, 但还需要知道对事务做出更改的内容是否在该范围内,比如End的那个2是已提交的还是未提交的……
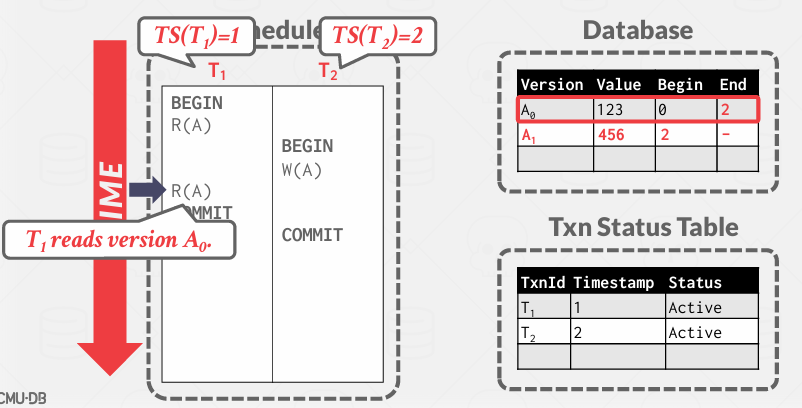
事务1 Read A, 那么就会去读取旧版本,因为当前事务是1介于0和2之间
因此这个例子实际上 解决了可重复度的问题
因为我们正在从记录的生命周期中划分,随着时间的推移,他将在时刻改变状态, 所以我们始终知道在给定的时间点上我的事务应该读取哪个版本
如果该版本不可见,就必须等待,并且对该对象施加写锁。
所以,版本机制仅仅是一种机制,仍需要拥有并发控制协议防止写入路径冲突
Example 2
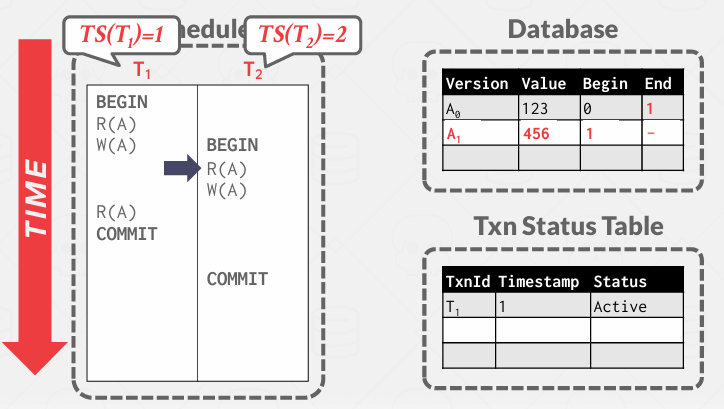
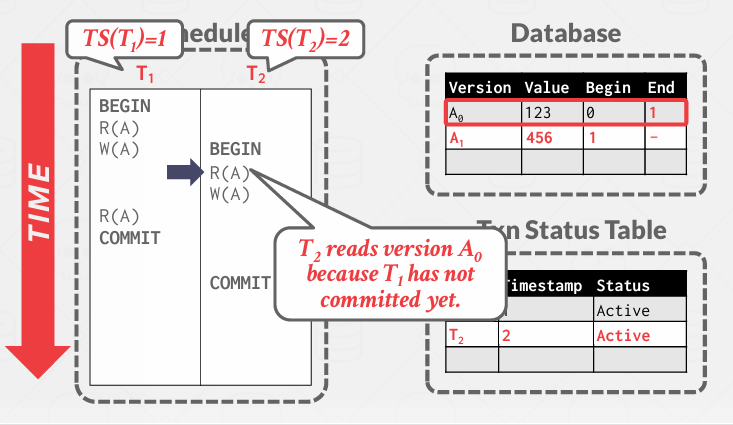
T2读取A0版本, 因为T1还没有提交 这是允许的
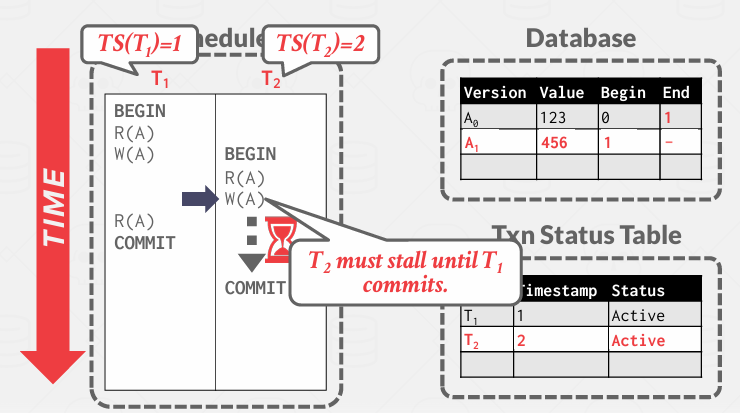
但是T2想写就不被允许, 因为它需要创建版本链中的新条目, 而现在其实T1正在创建新条目
我觉着这里本质上只有一条版本链 T1占着呢 后面可能还会续
其实就像T2想要写入的时候 会检查 结果发现持有锁了
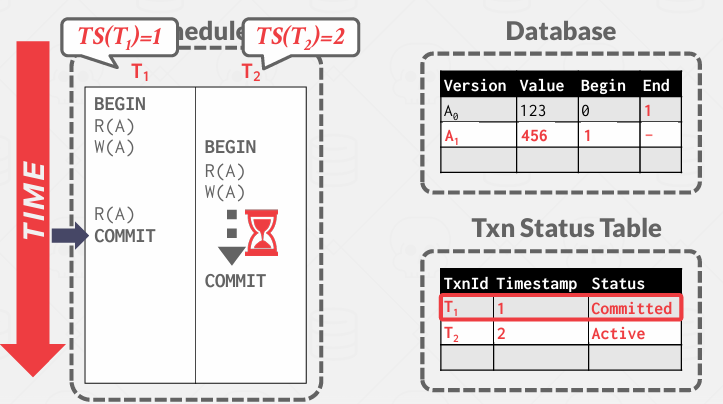
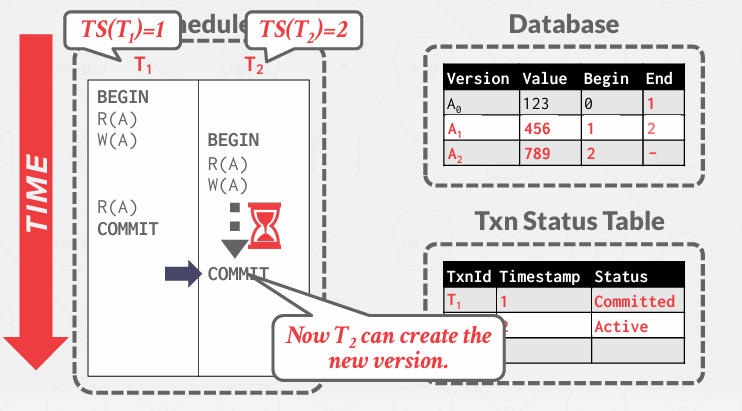
所以说仍然需要锁来保护正在更新的东西和链。 -> 因此MVCC只是维护版本,仍然需要向2PL这样的协议来保护它
Snapshot Isolation(SI) 快照隔离
快照隔离级别比可串行化级别低一级, 缺了一个称为Write Skew Anomaly(写入倾斜异常)的东西,这是除了前面提到过得不可重复读, 脏读, 丢失修改, 幻读等之外另一种需要了解的异常

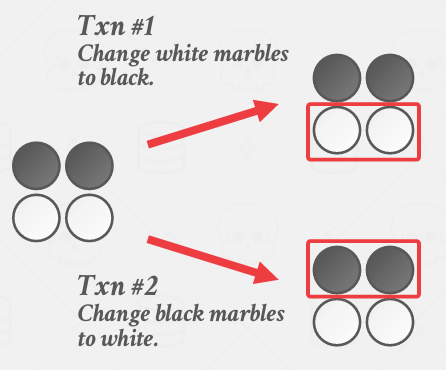
上面的事务想变成white变成black, 下面的事务想把black变成write
使用快照隔离,同时制作一个副本
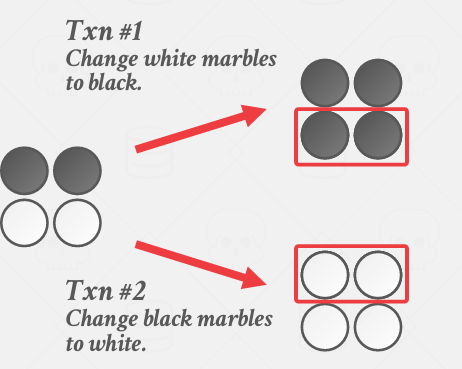
当合并回去的时候
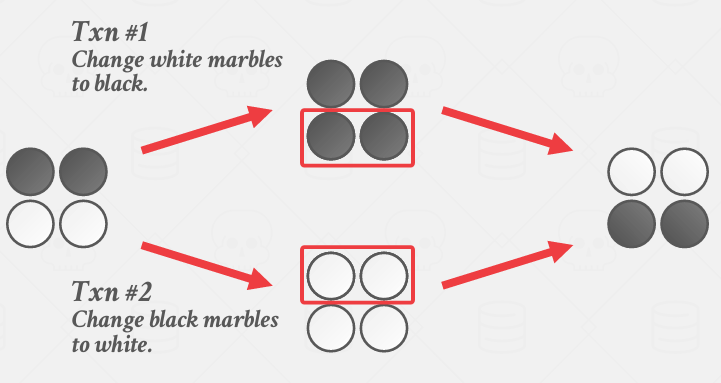
这显然是错误的,因为这是不可串行化的 按说我们应该在事务2之前得到的是全是黑的,事务2后事全是白的
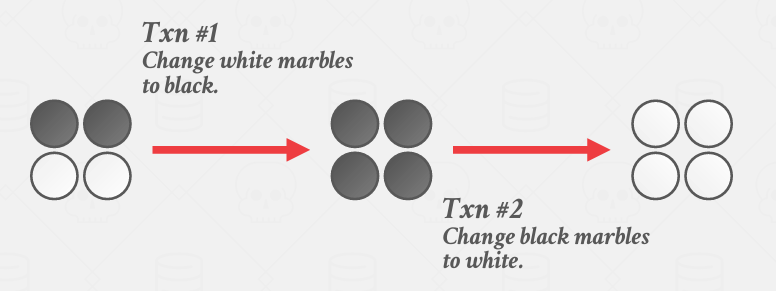
哈哈哈哈哈几乎所有现代系统都会采用多版本并发控制

MVCC Design Decisions
现在我们将深入探讨除了MVCC之外,我们还需要其他组件的细节, 比如之前所讨论过的, 需要一个版本控制组件。除此之外,我们还有几项关于MVCC设计考虑的议题需要讨论,但总共有:
- Concurrency Control Protocol 并发控制协议
- Version Storage 版本存储
- Garbage Collection 垃圾收集
- Index Management 索引管理
- Deletes 删除
Concurrency Control Protocol
我们已经讨论了一系列并发协议,包括OCC, 2PL……
而理解MVCC的最佳方式是将其视为一种机制,他告诉你如何维护多个版本, 我们仍需通过并发控制协议来保护该机制(前面提到过)
MVCC的基本原理是创建一个不同版本的链表,但是在上面的例子其实我们也看到了,在某些时刻,在有某个写入者在进行写入操作并创建新版本的时候,我们必须防范两个人都试图写入并创建新值之类的情况。
换句话说就是没法像git一样分支,只能等一个续完了 另一个接着续 形成一条链
因此,引入一个并发控制机制是我们在维护这些版本机制之外所必须的
而版本控制机制的一个妙处在于,如果我作为一个事务正在读取某些数据,且时间戳允许,就能读取一个较旧的版本,而读取者可以绕过写入者继续进行。如果读者有正确的时间戳或具备适当的串行化顺序使得他们通行,那么写者就不会阻塞读者
但是如果在2PL中获取的是写锁,那么读者也得等
- Approach 1: Timestamp Ordering
- Approach 2: OCC
- Approach 3: 2PL
Version Storage
我们维护的是一个单链表,组织数据的方式是什么? 如何存储这么版本?
- Approach 1: Append-Only Storage -- 仅附加存储,我将在其中创建链表,类似于我们在图中所见的,即在同一表中,记录所在的位置
- Approach 2: Time-Travel Storage -- 我将创建表的第二个版本,所有版本都在此维护
- Approach 3: Delta Storage -- 首选方法: 增量存储
Append-Only Storage
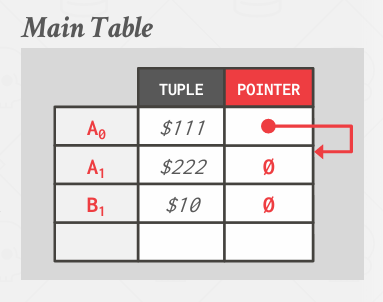
现在有两条记录A和B, 虽然只显示了一个值,但也是完整的记录
在Append-Only Storage中,当创建新版本的时候,实际上是在同一表中创建一个新纪录,这个表或物理文件负责追踪其中的所有记录.
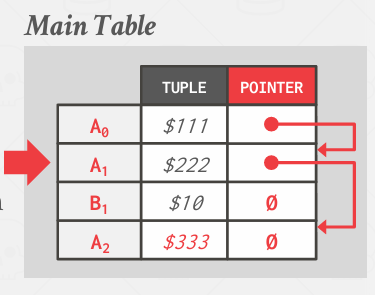
多了一个Pointer, 这个指针包含了起始时间戳以及与之关联的一堆其他信息
所以对于Append-Only Storage来说, 只需要创建新版本, 并在内部维护这些指针
可以将其视为使用分槽页组织来创建文件,在这个分槽页中有record id, 这个A0, A1可能是id, 然后通过Pointer将这些记录连接在一起,使得能够维护我们的单向链表
Version Chain Ordering
有一个有趣的问题是 这个 版本的 单链表的顺序问题,对于新版本实在链的末端?还是链的开始?
其实两种方式都可以,但是每种方式都有利弊
从易于实现的角度来看,实现一个从最旧到最新的排序是非常简单的,就像上面的例子中做的;当然在找的时候,需要遍历整个链表,并注意到这些链可能实际上分布在多个页面上.
另一种方法是从最新到最旧,但这样实现起来更困难,逻辑上,需要创建新纪录,移动所有内容
但这两种方法都设计到一个微妙的问题,索引如何引用记录ID? 比如,如果我创建了记录A的第三个版本,我有一个索引,他该指向哪一个呢?
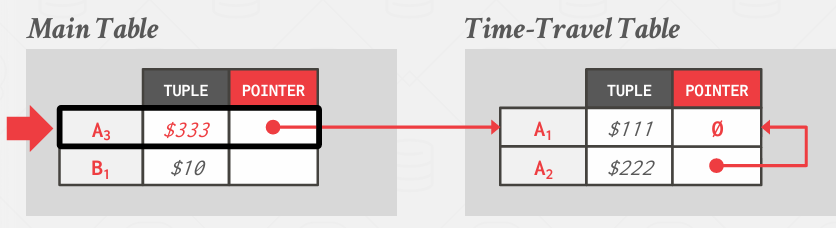
Time-Travel Storage
这是在原先没有MVCC情况下,后来又整合了MVCC系统的系统
采用类似的方法可以使得现有存储结构的最小干扰性改动
这里的思想是,如果我有一条新的记录A2,将会放在main table,而旧值放在time-travel table
显然这种方法的成本更高,因为无法实现局部性追踪问题,但并不会打乱主表
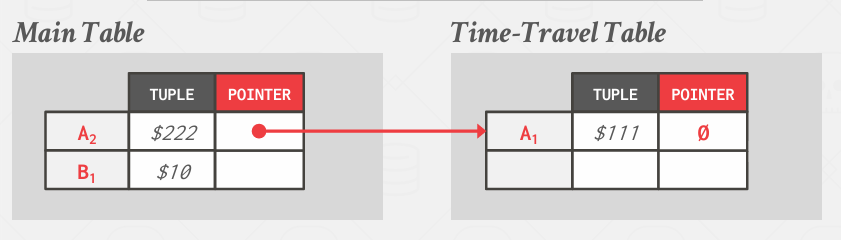
如果要更新,就是下面的步骤
先将A2复制到旧表
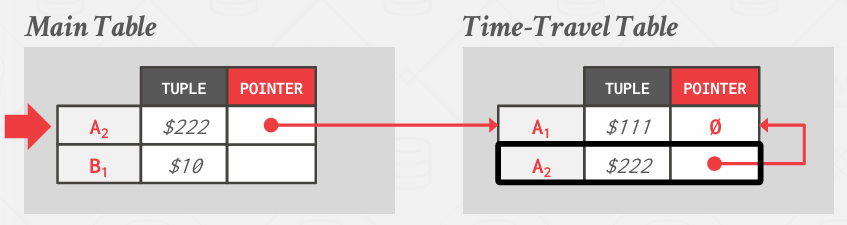
然后跟新main table中到新的值
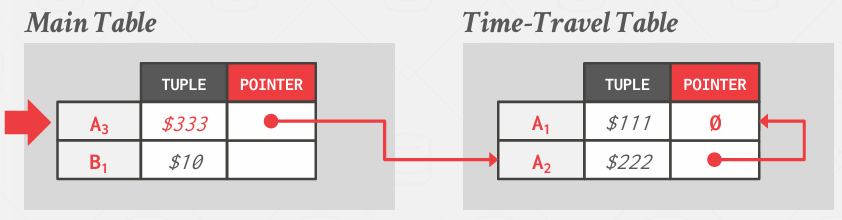
更新pointer
Delta Storage
到目前为止,所有这些存储,如果对单列进行了更改,实际上实在制作整个记录的完整副本,只不过不知道为啥哈哈哈他用的例子就只有一列啊。
而Delta Storage做的事儿就是仅取所更改的值,当然在给定记录中更改的值可能不止一个,并将这些值存储在Delta Storage Segment
像这样
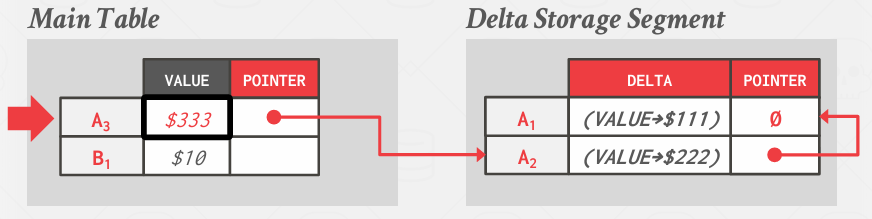
当然这里的包括上面的操作都是分步进行的,所以说应该得是原子性的,所以就涉及到后面探讨的恢复机制,我们会记录日志以便在开始进行变更后,若中途遭遇崩溃,能够回退到某个安全状态
如果想拿到最版本的记录的话,就不是直接取出来了 而是用反向增量 只替换个别列 那么算出来
Garbage Collection
一旦引入了版本管理, 垃圾收集也变得必不可少,因为在不断构建版本链的过程中,许多更新,会发生在某个记录上, 在某个时刻, 版本链会积累起来。当reader不断进入,reader的时间戳变新,没有任何读者的时间戳是古老的,我们就需要清理那些版本
我们需要关注的点是
- 怎样去查找过期的版本
- 怎样/何时回收这些旧记录是安全的?
现在,当确认安全时, 通常会指派事务号或时间戳给事务, 以标识过期版本。因此,有了一个方法去判断并确定在这个版本链的尾部,可以去舍弃哪一部分
现在的问题是,当你需要这种类型的垃圾回收的时候,你已经确定了哪些可以丢弃,你打算何时开始工作?
存在两种方法
- Approach 1: Tuple-level. 在元组级别进行操作, 即逐个遍历链表.
- 1: Backgournd Vacuuming(后台清理), 即由后台线程执行此操作;
- 2: Cooperative Cleaning(协作清理), 在一定程度上自行优化表结构
- Approach 2: Transaction-level. 事务级别进行操作
Tuple-level GC 1: Background Vacuuming
我有一个启动的后台清理线程, 每隔一段时间,就会遍历所有存放版本的地方,他会知道最新交易的最小的时间戳 然后根据这个时间戳清理掉不需要的东西
example
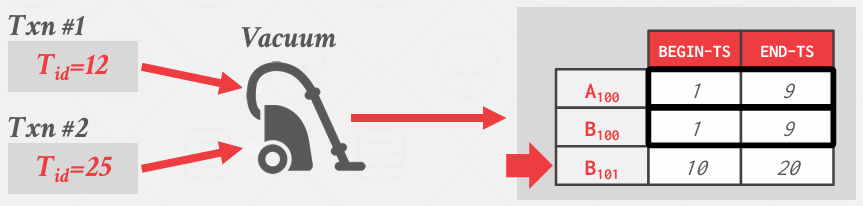
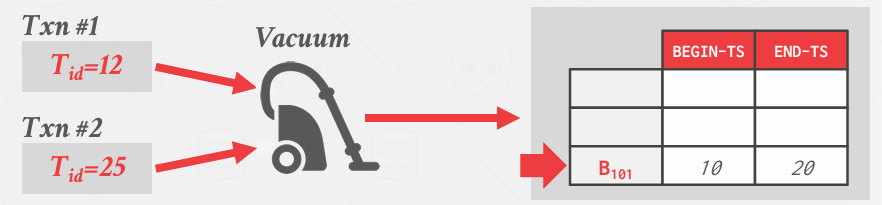
这个版本链可能很长,可能跨越不同的页面等等,因此,这个清理过程可能会相当耗费资源, 它正在对整个数据库进行广泛的修改,显然这不仅仅是一个表, 一个文件的问题, 而是所有表都需要具备这种所需的版本管理功能
一种优化是不必从第一页到最后一页逐个文件从头到尾的扫描,而是采取更高效的方法, 每当页面上发生某更新时,将记录一个简单的元数据,其中可能包含每个页一位,用于标记该页为"脏页"
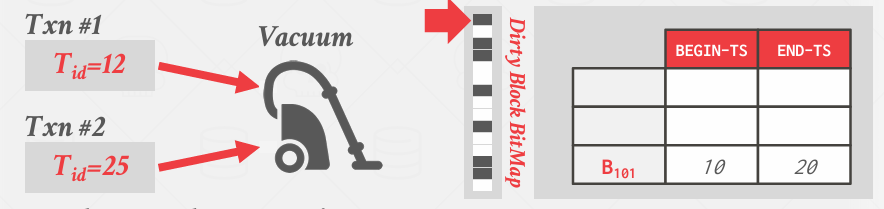
Tuple-level GC 2: Cooperative Cleaning
协同清理, 就如同在一家坐下来用餐的餐厅, 服务员会为你呈上所有食物,并在用餐结束后将盘子收走。在协同清理过程中, 工作人员在执行任务时会自行识别并清理需要处理的区域
假设Txn想获取A的值,假设我们使用的是从旧到新, 所以一开始找的时候就是从旧的开始找,那么找过一个旧的不合适旧可以清理掉



其实我感觉有点均摊的那个意思
Transaction-level
每个事务都会跟踪其所执行的所有操作,包括哪些因创建新版本而即将被淘汰的内容
在这种方法中,随着事务的进行,它会执行一次更新,紧接着第二个操作介入,此时便产生了这些旧版本
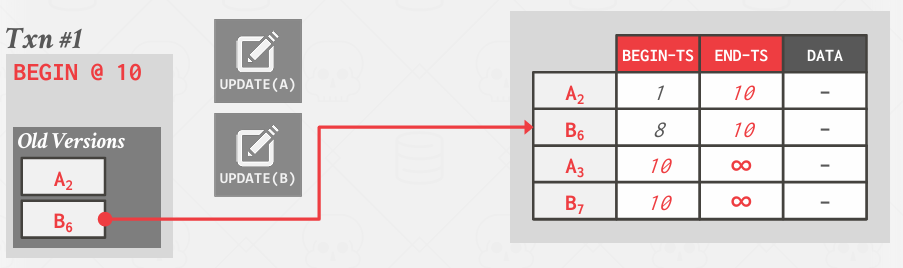
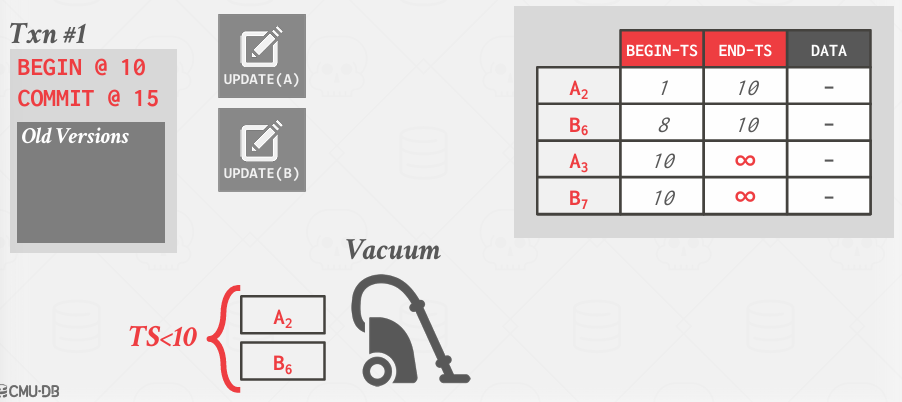
基本的情况就是,当一个事务完成时,它知道我创建了两个版本,一个是记录A的版本,另一个是记录B的版本。这个时候就能启动一个清理过来处理这些版本
Index Management
假设我有一个主键索引,我如果要更新主键,通常在为主键更新实现版本控制机制时,基本上将其视为一个删除操作后面加一个插入操作。这样可以使语义清晰,并且不会形成版本链,因为删除后一切都不存在了,随后再进行插入。
当随着二级索引的引入,问题变得更加有趣,会更加负责
二级索引指针的两种实现方式
- Logical Index: 使用一个“固定的、不会变化的标识符”(比如 主键值或 Tuple ID)来定位一条逻辑记录。
- Physical Index: 直接在二级索引中存储数据记录在磁盘或内存中的“物理位置”,即指向版本链头部的指针。
二级索引是指数据库表中非主键字段上建立的索引,用于提高基于这些字段的查询效率。
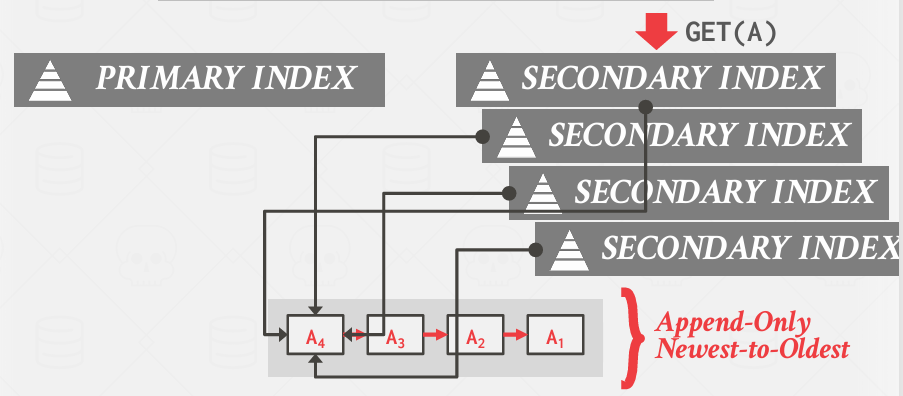
但其中一个内容改了,有了新的版本,所有的二级索引都得去改
间接性是 计算机专业中一个很好的解决方案
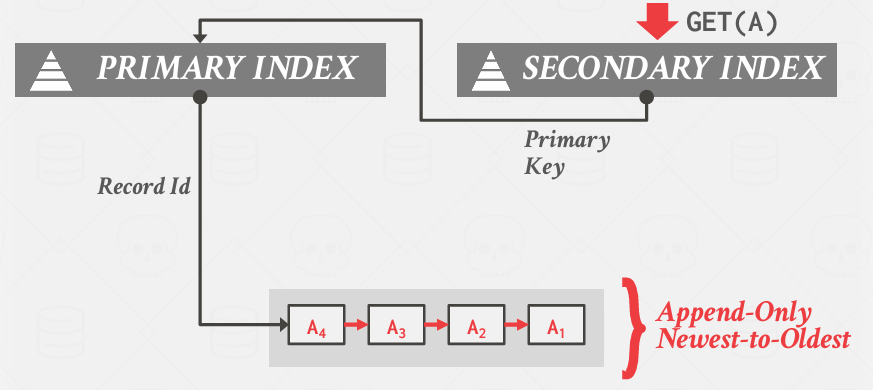
与其让二级索引指向记录ID, 如果让主键类似于记录ID, 二级索引指向主键,这意味着当我通过二级索引访问数据的时候,必须先找到主键,然后在获取记录ID, 但是如果热点数据在缓冲池中,其实也没啥事儿
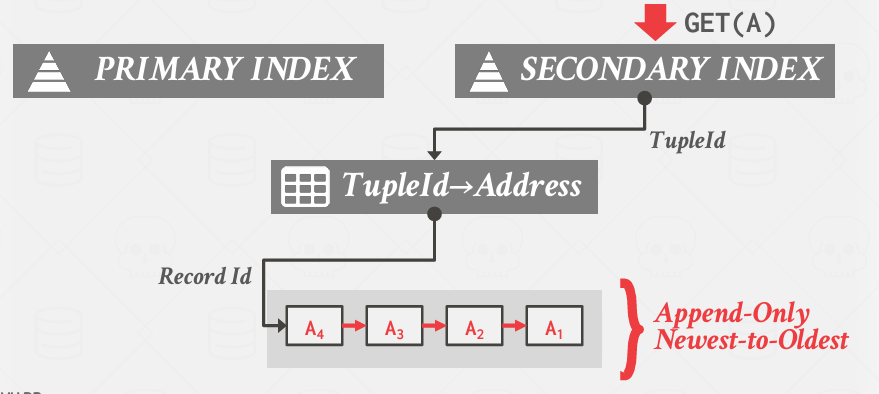
还有一种间接寻址的方式是设想存在一个全局结构,有点像哈哈哈page table那种结构了哈 能见元组ID转换为某种地址,可以这么做,但没必要,因为主键的作用就是这个作用
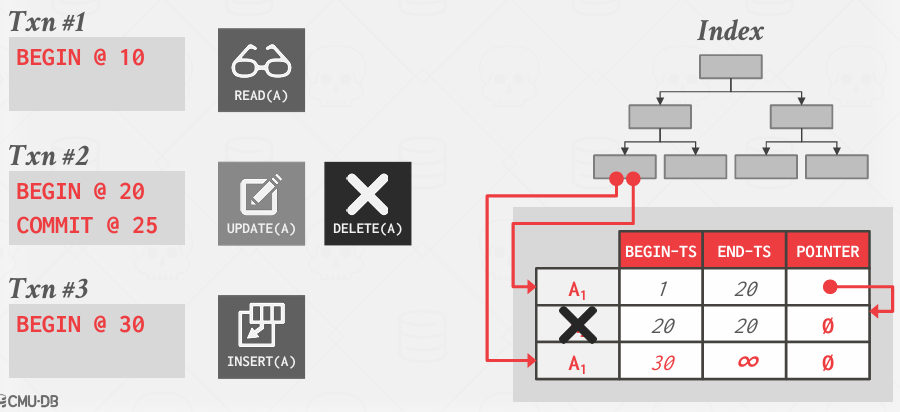
MVCC Duplicate Key Problem
由于MVCC看起来似乎允许键的重复,事实证明,即使是主键,如果采用的是更新主键并保留版本的方式,那么在某种程度上,如果你考虑B树的实现方式,通常对于主键,我会实现为确保我永远不会有一个重复的键,但某种意义上,键可以暂时拥有重复,可能需要这种重复一小段时间
这里不会深入了解细节 由于课程进度的原因 自己看
MVCC Deletes
实现删除的功能有很多种,可以通过保留删除标记或墓碑标记来实现
这一部分也是自行阅读
- Approach 1: Deleted Flag -- 给每条记录加一个是否被删除的flag, 当执行
DELETE时,并不删除记录,而是把标志设为“已删除”。标志可能放在tuple header或者是专门的一列 - Approach 2: Tombstone Tuple
- 所有记录版本通过version chain连接成链。
- 墓碑是这个链上的最新版本,表示该逻辑记录已删除。
- 这个墓碑元组是空的,没有内容,或只包含最小信息。
- 通常将这些墓碑放在单独的内存池或数据结构中,通过特殊位模式(bit pattern)标记其为墓碑,降低空间开销。
MVCC Implementations

两篇论文推荐
- Andy老师的一篇关于内存中MVCC的论文
- 了解某一个特定协议的细节: 推荐阅读Hackathon